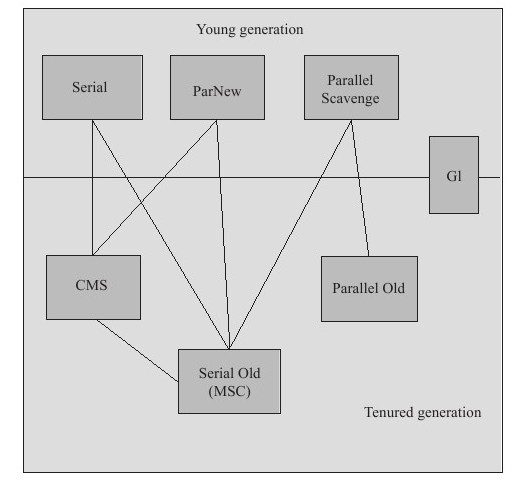
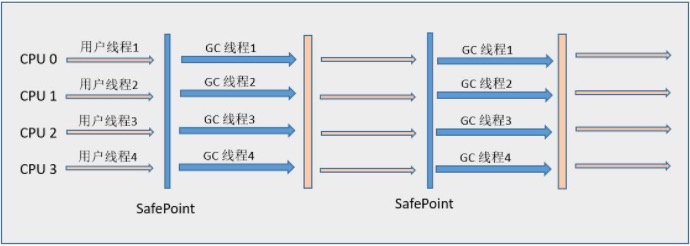
ParNew收集器就是Serial收集器的多线程版本,它也是一个新生代收集器。除了使用多线程进行垃圾收集外,其余行为包括Serial收集器可用的所有控制参数、收集算法(复制算法)、Stop The World、对象分配规则、回收策略等与Serial收集器完全相同。 该虚拟机是许多运行在Server模式下的虚拟机中首选的新生代收集器,其中有一个与性能无关的重要原因是,除了Serial收集器外,目前只有它能和CMS收集器(Concurrent Mark Sweep)配合工作。它默认开启的收集线程数与CPU的数量相同,在CPU非常多的情况下可使用-XX:ParallerGCThreads参数设置。
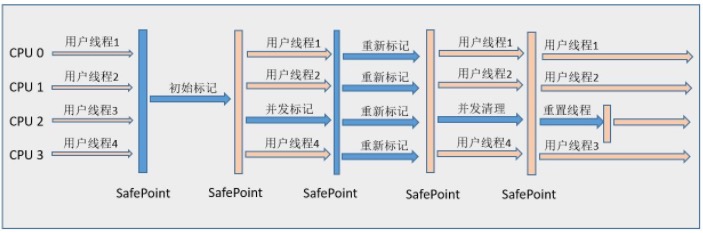
CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器,它非常符合那些集中在互联网站或者B/S系统的服务端上的Java应用,这些应用都非常重视服务的响应速度。从名字上(“Mark Sweep”)就可以看出它是基于“标记-清除”算法实现的。 CMS收集器工作的整个流程分为以下4个步骤:
初始标记(CMS initial mark):仅仅只是标记一下GC Roots能直接关联到的对象,速度很快,需要“Stop The World”。
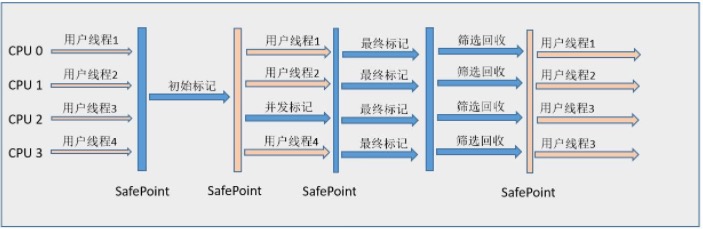
最终标记(Final Marking) 为了修正在并发标记期间因用户程序继续运作而导致标记产生变动的那一部分标记记录,虚拟机将这段时间对象变化记录在线程的Remembered Set Logs里面,最终标记阶段需要把Remembered Set Logs的数据合并到Remembered Set中,这阶段需要停顿线程,但是可并行执行。
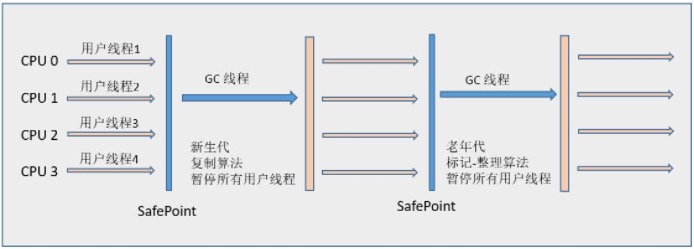
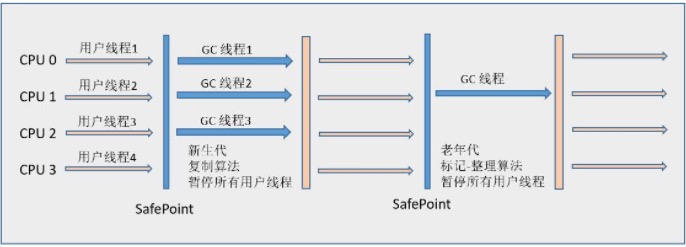
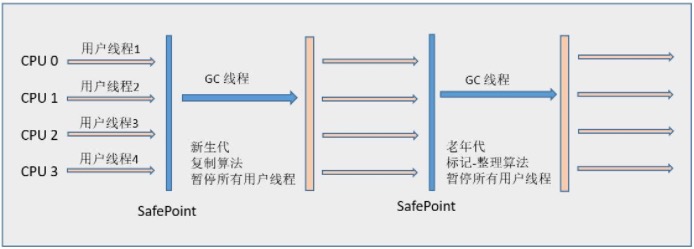
筛选回收(Live Data Counting and Evacuation) 首先对各个Region中的回收价值和成本进行排序,根据用户所期望的GC 停顿是时间来制定回收计划。此阶段其实也可以做到与用户程序一起并发执行,但是因为只回收一部分Region,时间是用户可控制的,而且停顿用户线程将大幅度提高收集效率,流程图如下:
// Destroy already created singletons to avoid dangling resources. destroyBeans();
// Reset 'active' flag. cancelRefresh(ex);
// Propagate exception to caller. throw ex; }
finally { // Reset common introspection caches in Spring's core, since we // might not ever need metadata for singleton beans anymore... resetCommonCaches(); } } }
// Recursively process any member (nested) classes first processMemberClasses(configClass, sourceClass);
// Process any @PropertySource annotations for (AnnotationAttributes propertySource : AnnotationConfigUtils.attributesForRepeatable( sourceClass.getMetadata(), PropertySources.class, org.springframework.context.annotation.PropertySource.class)) { if (this.environment instanceof ConfigurableEnvironment) { processPropertySource(propertySource); } else { logger.warn("Ignoring @PropertySource annotation on [" + sourceClass.getMetadata().getClassName() + "]. Reason: Environment must implement ConfigurableEnvironment"); } }
// Process any @ComponentScan annotations Set<AnnotationAttributes> componentScans = AnnotationConfigUtils.attributesForRepeatable( sourceClass.getMetadata(), ComponentScans.class, ComponentScan.class); if (!componentScans.isEmpty() && !this.conditionEvaluator.shouldSkip(sourceClass.getMetadata(), ConfigurationPhase.REGISTER_BEAN)) { for (AnnotationAttributes componentScan : componentScans) { // The config class is annotated with @ComponentScan -> perform the scan immediately Set<BeanDefinitionHolder> scannedBeanDefinitions = this.componentScanParser.parse(componentScan, sourceClass.getMetadata().getClassName()); // Check the set of scanned definitions for any further config classes and parse recursively if needed for (BeanDefinitionHolder holder : scannedBeanDefinitions) { if (ConfigurationClassUtils.checkConfigurationClassCandidate( holder.getBeanDefinition(), this.metadataReaderFactory)) { parse(holder.getBeanDefinition().getBeanClassName(), holder.getBeanName()); } } } }
// Process any @Import annotations processImports(configClass, sourceClass, getImports(sourceClass), true);
// Process any @ImportResource annotations if (sourceClass.getMetadata().isAnnotated(ImportResource.class.getName())) { AnnotationAttributesimportResource= AnnotationConfigUtils.attributesFor(sourceClass.getMetadata(), ImportResource.class); String[] resources = importResource.getStringArray("locations"); Class<? extendsBeanDefinitionReader> readerClass = importResource.getClass("reader"); for (String resource : resources) { StringresolvedResource=this.environment.resolveRequiredPlaceholders(resource); configClass.addImportedResource(resolvedResource, readerClass); } }
// Process individual @Bean methods Set<MethodMetadata> beanMethods = retrieveBeanMethodMetadata(sourceClass); for (MethodMetadata methodMetadata : beanMethods) { configClass.addBeanMethod(newBeanMethod(methodMetadata, configClass)); }
// Process default methods on interfaces processInterfaces(configClass, sourceClass);
// Process superclass, if any if (sourceClass.getMetadata().hasSuperClass()) { Stringsuperclass= sourceClass.getMetadata().getSuperClassName(); if (!superclass.startsWith("java") && !this.knownSuperclasses.containsKey(superclass)) { this.knownSuperclasses.put(superclass, configClass); // Superclass found, return its annotation metadata and recurse return sourceClass.getSuperClass(); } }
// No superclass -> processing is complete returnnull; }